LSTM 心得
RNN
RNN 其本質上就是一個具狀態的 NN,他跟其他 NN 不同的地方就在於他多了一個輸入,表示上一個狀態(Hidden State)
如下圖所示
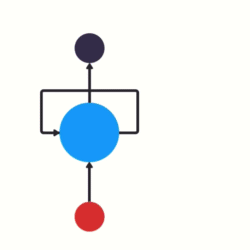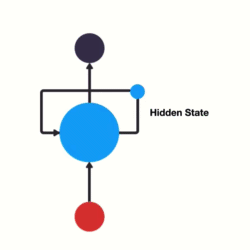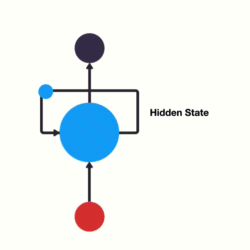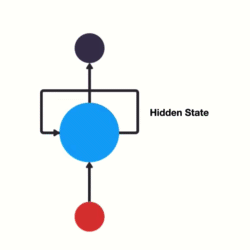
1 RNN 示意圖
RNN 缺點
而隨之帶來的問題即是梯度消失 or 爆炸的問題
因 RNN 在計算時,是以乘法為主,而乘法有一個特性,那就是很容易使數值太大或太小,
例如 (1.01) 的 365 次方 會是 37.7834343329,
而 (0.99) 的 365 次方 則是 0.02551796445,
因此如果網路很深,句子很長,遇到太長句子時,在 Backward Propagation (反向傳播) 很容易使數字太大或太小,造成梯度爆炸或消失的問題,使越前面的句子,其參數很難被 RNN 更新的很好。
也因此,越是前面的句子,越難被 RNN 所利用 (因為其參數更新不好),也因此造成 RNN 僅能很好的利用靠近句子結尾的幾個字而已。
1 RNN 反向傳播 示意圖
LSTM

LSTM 架構圖 出處
那要怎麼解決呢? LSTM 提出的做法是透過多一個狀態來保存長距離訊息
LSTM 結構
$\sigma$ 控制著資訊流過去的百分比 (0 ~ 1)
$tanh$ 則是代表資訊的數值 (-1 ~ 1)
Forget gate (最左邊的 $\sigma$)
從圖中可以很明顯的看出,
決定長距離訊息 C 有多少要用到
Input gate (中間的黃色 $\sigma\ &\ tanh$)
決定多少短距離訊息要被更新到 C 裡面
Output gate(最右邊的區域)
決定什麼要進入隱藏狀態中
GRU
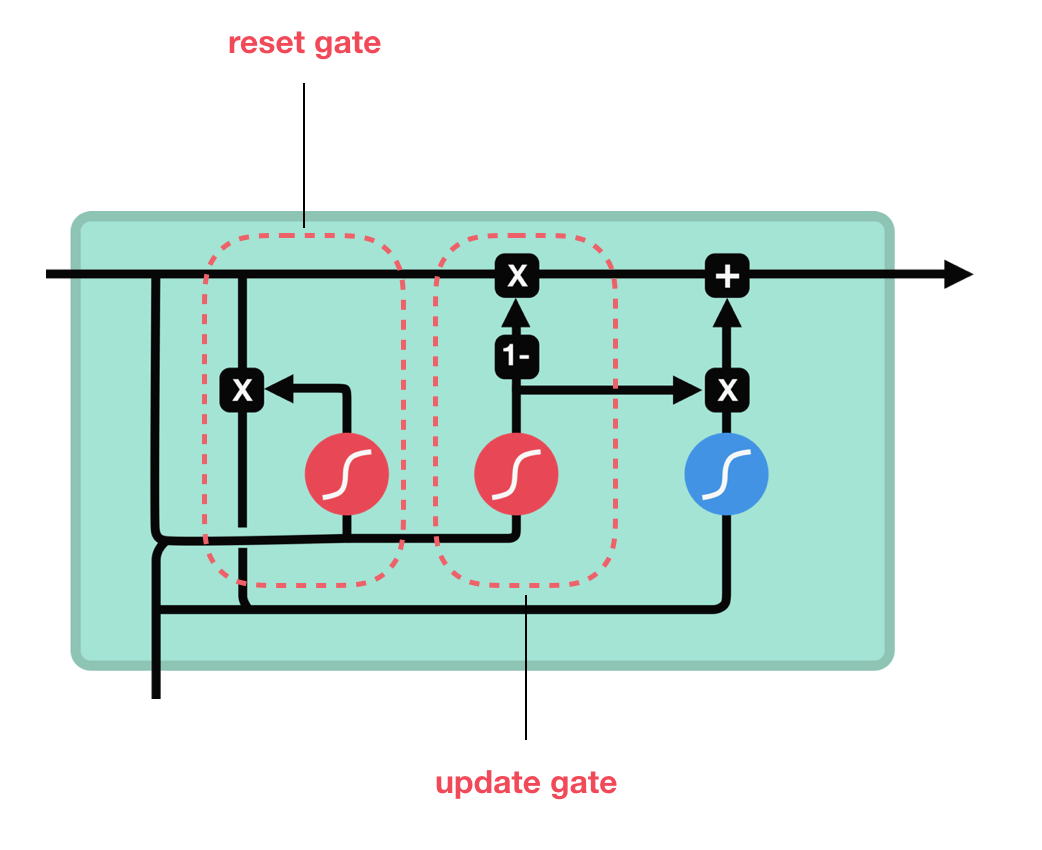
2 GRU 架構圖